
🔗 Colab Notebook
Description
In this project, I implemented the paper Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. The neural network, a combination of CNN and LSTM, was trained on the MS COCO dataset and it learns to generate captions from images.
As the network generates the caption, word by word, the model’s gaze (attention) shifts across the image. This allows it to focus on those parts of the image which is more relevant for the next word to be generated.
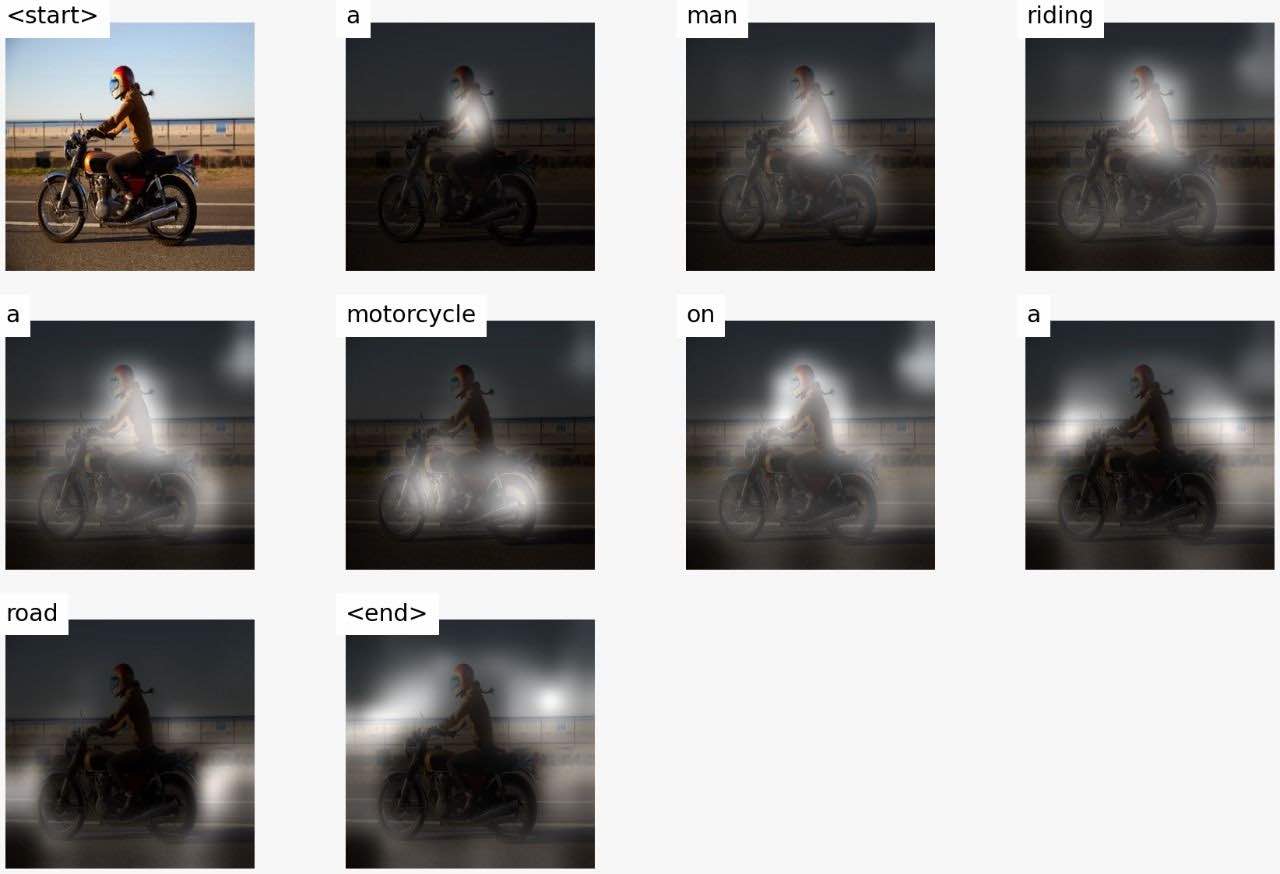
Furthermore, beam search is used during inference to enhance the prediction result. The network was trained in PyTorch on an Nvidia GTX 1060 graphics card for over 80 epochs.